
Sempre ouvi e li que os grandes vilões da produtividade de um sistema são os delays ocasionados pelo tempo de espera em filas. Tenho certeza que você também já ouviu ou leu algo sobre isso. Da mesma forma, os estoques representam uma das maiores causas de desperdício, especialmente para a manufatura.
Mas, pensando em desenvolvimento de software, será que as filas e estoques de demandas (qualquer item de trabalho de uma equipe de software, como histórias de usuários, bugs, etc…) se comportam da mesma maneira e trazem as mesmas consequências em todos os estágios do fluxo de desenvolvimento? Serão essas consequências sempre negativas?
Para respondermos essas questões, consideremos uma equipe que trabalha com o workflow composto pelas seguintes etapas:
- Backlog: Itens já escritos pelo PO (Product Owner) e que ainda precisam ser refinados com a equipe;
- Ready to Dev: Itens que já foram refinados com a equipe e estão aguardando o início do desenvolvimento;
- In Development: Itens em desenvolvimento;
- Ready to Test: Itens desenvolvidos e aguardando testes;
- Testing: Itens sendo testados pelo time de QA (Quality Assurance);
- Ready to Deploy: Itens já aprovados por QA e aguardando o deploy em produção;
- In Production: Itens em produção.
Da lista acima, conseguimos identificar algumas etapas de filas, onde seria possível acumular estoques de demandas aguardando as próximas etapas. São elas: Backlog, Ready to Dev, Ready to Test e Ready to Deploy.
Como será que os estoques se comportam em cada uma dessas etapas?
Estoque em Backlog?
Cenário: como já tinha uma ideia do que seria trabalhado pelos próximos meses, o PO da equipe decidiu escrever uma grande quantidade de histórias de usuário.
Para este cenário, há um risco considerável de desperdício do esforço do PO e até das histórias de usuário escritas, uma vez que que podem ocorrer mudanças na estratégia do produto. Por exemplo, um concorrente lançou uma nova feature que não estava mapeada e decidiu-se implementá-la também. Novas histórias precisarão ser escritas e outras possivelmente serão fechadas como obsoletas.
Estoque em Ready to Dev?
Cenário: o PO da equipe sairá de férias nos próximos dias e não haverá um substituto. Nos últimos dias de trabalho antes do descanso, o PO e a equipe se esforçaram para refinar uma grande quantidade de histórias de usuário para que a equipe trabalhasse durante o período.
Neste caso, há um risco maior de que os acordos entre PO e equipe, discutidos durante os refinamentos, sejam esquecidos com o passar do tempo (é sempre melhor que esses acordos estejam frescos na cabeça da equipe).
Porém, trata-se de uma opção bastante interessante para que a equipe não sofra de starvation durante a ausência do PO. Além de ser uma opção melhor do que deixar as histórias de usuários na etapa anterior (Backlog), o que poderia elevar o risco de desalinhamento entre o que era planejeado e o que será desenvolvido.
No geral, é importante ter bem claro quem pode tomar as decisões do produto em caso de ausência do PO, pois, mesmo com a adoção dessa estratégia de estoque, dúvidas e incertezas certamente surgirão na sequência do processo. Em muitos casos, essa responsabilidade acaba ficando com alguém da equipe de design, um facilitador do processo ou mesmo com a própria equipe de desenvolvimento, que pode tomar as decisões em conjunto.
Estoque em Ready to Test?
Cenário: o responsável pelo QA da equipe ficará ausente por algumas semanas para realização de uma cirurgia. A equipe optou por continuar o desenvolvimento das histórias de usuário e deixá-las acumulando em ‘Ready to Test’ até o retorno do QA.
Para esta abordagem, como as funcionalidades não serão testadas até o retorno do responsável pelo QA, o ciclo de feedback será mais longo. Isso trará desvantagens como:
- Aumento no WIP (trabalho em progresso): das filas que discutimos até aqui, esta é a primeira em que há código em progresso sendo estocado (nas anteriores, já havia esforço de análise e design). Com isso, a quantidade de WIP no sistema tende a aumentar, e o Wesley Zapellini já nos explicou em seu e-book “5 Estratégias para otimizar o fluxo de desenvolvimento de software” os principais efeitos colaterais de ter o WIP alto.
- Redução da visibilidade do processo: com mais tarefas no board da equipe, tende a ficar mais complicado ter visibilidade do que está realmente em andamento.
- Redução da previsibilidade do processo: com a pausa do processo de testes, todas as tarefas que estiverem ou chegarem na fila de Ready to Test durante o período de ausência do responsável de QA ficarão por lá até o retorno dele, é claro. O lead time do processo (tempo entre o início do trabalho da equipe na demanda e o término dela) será, portanto, impactado.
- Aumento no número de bugs e não conformidades: como já mencionado no e-book “5 Estratégias para otimizar o fluxo de desenvolvimento de software”, o aumento do WIP tende a impactar diretamente na qualidade do software. Neste cenário, há ainda um ponto adicional: a falta de feedback quanto à conformidade das histórias desenvolvidas faz com que histórias sejam iniciadas com uma base já fora de conformidade, o que tende a sobrepor os problemas.
As imagens a seguir apresentam a distribuição do lead time das demandas da equipe imediatamente antes e após as férias do profissional de QA (para entender melhor os gráficos, recomendo o blogpost do Raphael Albino “Métricas Ágeis: o que Lead Time fala sobre seu projeto”). Na primeira delas, antes do início das férias do profissional, é possível ver que há pouca variabilidade no lead time das entregas e pouco WIP.
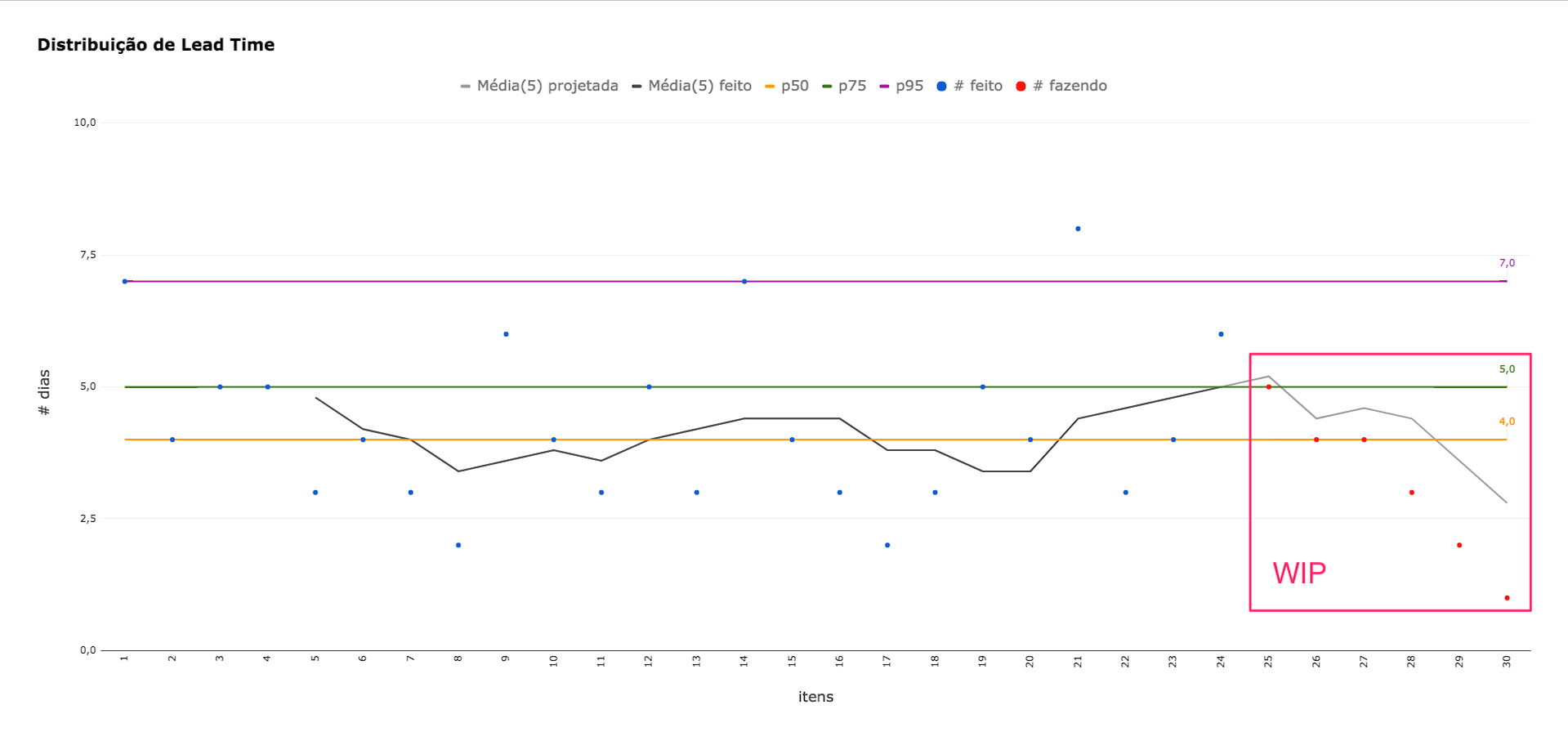
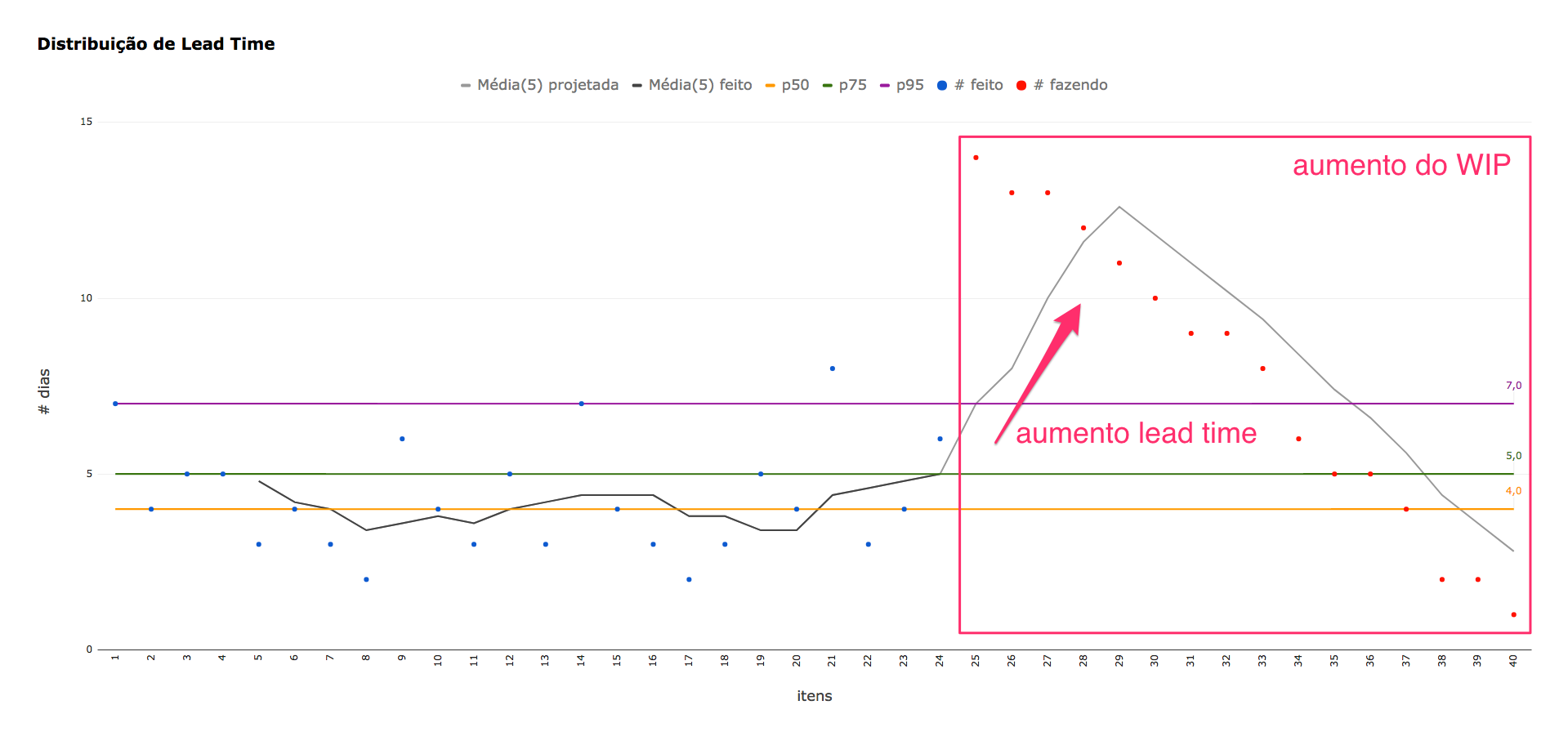
Já após as férias, é possível perceber uma tendência de aumento no lead time (média projetada já bastante acima do percentil 95%), o que deve contribuir para uma redução na previsibilidade das entregas. Além disso, é possível ver que a quantidade de trabalho em progresso também teve um aumento considerável:
Já vimos os possíveis impactos dessa estratégia, mas o que podemos fazer em uma situação como esta? Supondo que não haja outro profissional de QA disponível para a equipe, alguém do time pode assumir essa atividade ou, o que temos feito com sucesso em alguns contextos, a equipe como um todo pode se dividir para realizar os testes: sempre que alguém mover uma demanda para QA, antes de iniciar uma nova, pode verificar se há alguma pendente de testes e já puxá-la. A única sugestão é para que uma demanda não seja testada pela mesma pessoa que a desenvolveu.
Estoque em Ready to Deploy?
Cenário: por opção do PO, decidiu-se que todas as histórias mapeadas inicialmente precisariam estar prontas para que as novas features fossem para produção.
Neste caso, o maior impacto do ponto de vista do processo é que será preciso garantir que essas histórias praticamente prontas não criem um empecilho para que outras linhas de desenvolvimento integrem código em produção. De maneira geral, a sugestão é integrar código pronto em produção sempre que possível (há técnicas para se fazer isso sem necessariamente liberar as funcionalidades para os usuários, como a técnica de Feature Toggle). Além de desbloquear futuros deploys que precisem “passar na frente” (como bug fixes, por exemplo), essa estratégia ainda permitirá que os deploys sejam mais tranquilos e sem grandes riscos.
Do ponto de vista de produto, e considerando o Cost of Delay conforme nos apresentou o Lucas Colucci em seu blog post “Quanto a empresa perde financeiramente quando o projeto atrasa?” sobre o assunto, é sempre interessante disponibilizar as novas features para o cliente, mesmo que todas as features planejadas no escopo de um projeto não tenham sido finalizadas.
Um outro cenário muito comum, especialmente em equipes maiores, é o da existência de janelas e filas para deploy. Geralmente, essa estratégia é adotada quando:
1. o ferramental de deploy/rollback exige tempo e trabalho manual (frequentemente, com recursos compartilhados por várias equipes),
2. quando há falta de confiança quanto à qualidade do que está sendo colocado no ar (alguém se perguntaria: será que o código está adicionando bugs?)
3. ou quando há muitas equipes trabalhando em um mesmo produto.
Essa burocracia para o deploy (horários pré-definidos, dias da semana permitidos, comitês para decidir o que vai e o que não vai pro ar…) contribuirá para atrasar a entrada das novas funcionalidades em produção. Para reverter esse cenário, o ideal é investir em cobertura de testes e em automações em geral (tanto da execução dos testes, quanto de deploy/rollback), o que fará com que o processo de colocar código novo no ar se torne mais simples e indolor, tanto para quem faz o deploy quanto para quem usa o produto.
Conclusão
Em geral, as filas e estoques no desenvolvimento de software, especialmente em contextos ágeis, trazem como consequência aumento no risco de desperdício de esforço e de oportunidades de negócio representadas pelas demandas em estoque, principalmente as que já estão mais próximas de serem finalizadas e que poderiam gerar receitas para a empresa ou melhorias para os usuários.
Porém, como vimos acima, há também outras consequências que variam conforme o estágio do fluxo de desenvolvimento em que a demanda está, podendo impactar na qualidade do código e aumentar o número de bugs, ou até evitar uma possível situação de starvation da equipe.
E você? Quais situações já enfrentou com estoques e filas em suas equipes? Deixe seus relatos e comentários abaixo!