
Welcome to the “A sneak peek at Ecto 3.0” series:
- Breaking changes
- Query improvements part 1
- Query improvements part 2
- Performance, migrations and more (you are here!)
We are back for one last round! This time we are going to cover improvements on three main areas: performance, upserts and migrations. If you would like to give Ecto a try right now, note Ecto v3.0.0-rc.0 has been released and we are looking forward to your feedback.
Better memory usage
One of the most notable performance improvements in Ecto 3.0 is that schemas loaded from an Ecto repository now uses less memory.
A big part of the memory improvements seen in Ecto 3.0 comes from better management of schema metadata. Every instance you have of an Ecto.Schema, such as a %User{}, has a metadata field with life-cycle information about that entry, such as the database prefix or its state (was it just built or was it loaded from the database?). This metadata field takes exactly 16 words:
iex> :erts_debug.size %Ecto.Schema.Metadata{}
16
16 words for a 64-bits machine is equivalent to 128 bytes. This means that, if you were using Ecto 2.0 and you loaded 1000 entries, 128 kbytes of memory would be used only for storing this metadata. The good news is that all of those 1000 entries could use the exact same metadata! That’s what we did in this commit. This means that, if you load 1000 or 1000000 entries, the cost is always the same, only 128 bytes!
After we announced Ecto 3.0-rc, we started to hear some teams already upgraded to Ecto 3.0-rc. Some of those repos are quite big and it took them less than a day to upgrade, which is exactly how upgrading to major software versions should be.
Ben Wilson, Principal Engineer at CargoSense, upgraded one of their apps to Ecto 3.0-rc and pushed it to production. Here is the result:
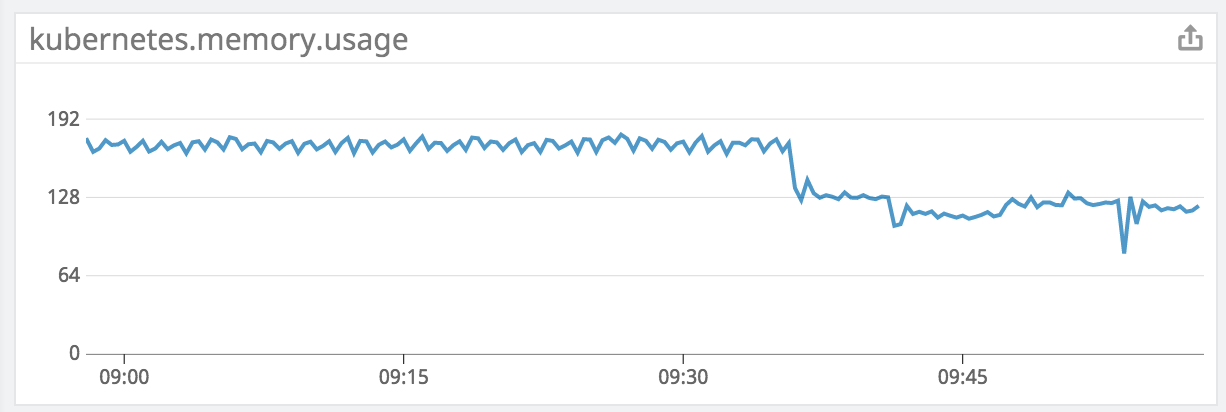
You can see the drop in memory usage from Ecto 2 to Ecto 3 at the moment of the deployment. This particular app loads a bunch of data during boot and we can clearly see the impact those improvements have in the memory usage. Once the system stabilized, the average memory use is 15% less altogether.
But that’s not all!
We also changed Ecto 3.0 to make use of the Erlang VM literal pool, which allows us to share the metadata across queries. For example, if you have two queries, each returning 1000 posts, all 2000 posts will point to the same metadata. These improvements alongside other changes to reduce struct allocation should reduce Ecto’s memory usage as a whole.
Statement cache for INSERT/UPDATE/DELETE
Another notable performance improvement in Ecto 3.0 comes from the fact Ecto now automatically caches statements emitted by Ecto.Repo.insert/update/delete.
Consider this code:
for i <- 1..1000 do
Repo.insert!(%Post{visits: i})
end
where Post is a schema with 13 fields. When running this code on my machine against a Postgres database with a pool of 10 connections, it takes 900ms to insert all 1000 posts. While Ecto has always cached select queries, once we also added the statement cache to Ecto.Repo.insert/update/delete, the total operation time is reduced 610ms!
But that’s not all!
Part of the issue here is that every time we call Repo.insert!, Ecto needs to get a new connection out of the connection pool, perform the insert, and give the connection back. For a pool with 10 connections, there is a chance the next connection we pick up is not “warm” and we may not hit the statement cache. While it is important to not hold connections for long, so we can best utilize the database resources, in this scenario we know we will perform many operations in a row.
For this reason, Ecto 3.0 includes a Repo.checkout operation, which allows you to tell the Ecto repository you want to use the same connection, skipping the connection pool and always using a “warm” connection:
Repo.checkout(fn ->
for i <- 1..1000 do
Repo.insert!(%Post{visits: i})
end
end)
With the change above, all of the inserts take 420ms on average.
There is one final trick we could use. Since we are performing multiple inserts, we could simply replace Repo.checkout by Repo.transaction. The transaction also checks out a single connection but it also allows the database itself to be more efficient. With this final change, the total time falls down to 320ms. And if you really need to go faster, you can always use Ecto.Repo.insert_all. Hooray!
More options around upserts
Ecto 2 added support for upserts. Ecto 3 brings many improvements to the upsert API, such as the ability to tell Ecto to :replace_all_except_primary_key in case of conflicts or to replace only certain fields by passing on_conflict: {:replace, [:foo, :bar, baz]}. This new version of Ecto also allow custom expressions to be given as :conflict_target by passing {:unsafe_fragment, "be careful with what goes here"} as a value.
There are many other improvements to the Ecto.Repo API, such as Ecto.Repo.checkout, introduced in the previous section, and the new Ecto.Repo.exists?.
Migrations
Another area in Ecto (or to be more precise, Ecto.SQL) that saw major improvements is migrations.
The most important change was a contribution by Allen Madsen that locks the migration table, allowing multiple machines to run migrations at the same time. In previous Ecto versions, if you had multiple machines attempting to run migrations, they could race each other, leading to failures, but now it is guaranteed such can’t happen. The type of lock can be configured via the :migration_lock repository configuration and defaults to “FOR UPDATE” or disabled if set to nil.
Another improvement is that Ecto is now capable of logging notices/alerts/warnings emitted by the database when running migrations. In previous Ecto versions, if you had a long index name, the database would truncate and emit an alert through the TCP connection, but this alert was never extracted and printed in the terminal. This is no longer the case in Ecto 3.0.
Similarly, Ecto will now warn if you attempt to run a migration and there is a higher version number already migrated in the database. Imagine you have been working on a feature for a long period of time and you were finally able to merge it to master. Since you started working on this feature, other features and migrations were already shipped to production. This may create an issue on deployment: in case something goes wrong when deploying this new feature and you have to rollback the database, the latest migrations by timestamp does not match the migrations that have just been executed.
By emitting warnings, we help developers and production teams alike to be aware of such pitfalls.
Summing up
We are very excited with the many improvements in Ecto 3.0. This short series of articles shares the most notable changes but there is much more. But perhaps the most important feature is that we have announced Ecto to be stable API and this is only possible due to the work that Plataformatec and the community has put into Ecto throughout the years. Enjoy!
