
There is a discussion that always comes up when dealing with database migrations.
Should I use the migrations to also migrate data? I mean, I’ve already altered the structure so it would be easy to change the data by including an SQL as well, and this would guarantee that everything is working after the deploy. Right?
It could work, but in most cases, it could also cause a database lock and a major production problem.
In general, the guidelines are to move the commands responsible to migrate the data to a separate task and then execute it after the migrations are up to date.
In some cases, this could also take an eternity when you are dealing with a database with millions of records. Update statements are expensive to the database and sometimes it is preferable to create a new table with the right info and after everything is ok to rename after the right one. But sometimes we don’t want or we simply just can’t rename the table for N reasons.
When you are dealing with millions of records and need to migrate data, one thing you can do is to create a SQL script responsible to migrate the data in batches. This is faster because you won’t create a single transaction in the database to migrate all records and will consume less memory.
One thing to consider when using migration scripts is to disable all indexes in the table, indexes are meant to improve the read performance but can slow down the write action significantly. This happens because every time you write a new record in the table, the database will re-organize the data. Now imagine this in a scenario of millions of records, it could take way too much then it should.
Every database has its own characteristics, but most of the things you can do in one, you can do in another, this is due to the SQL specification that every database implements. So when you are writing these scripts, it is important to always look at the documentation. I’ll be using PostgreSQL in this example, but the idea can be applied to most databases.
Let’s take a look into one example
Suppose we are dealing with e-commerce and we are noticing a slowness in the orders page, and by analyzing the query we notice an improvement can be done by denormalizing one of its tables. Let’s work with some data to show how this could be done.
CREATE TABLE "users" (
id serial PRIMARY KEY,
account_id int not NULL,
name varchar(10)
);
CREATE TABLE orders (
id SERIAL PRIMARY KEY,
data text not NULL,
user_id int not NULL
);
-- Generates 200_000_000 orders
INSERT INTO "users" (account_id)
SELECT generate_series(1,50000000);
INSERT INTO orders (data, user_id)
SELECT 't-shirt' AS data,
generate_series(1,50000000);
INSERT INTO orders (data, user_id)
SELECT 'backpack' AS data,
generate_series(1,50000000);
INSERT INTO orders (data, user_id)
SELECT 'sunglass' AS data,
generate_series(1,50000000);
INSERT INTO orders (data, user_id)
SELECT 'sketchbook' AS data,
generate_series(1,50000000);
CREATE index ON "users" ("account_id");
CREATE index ON "orders" ("user_id");
SELECT
"orders"."id",
"orders"."data"
FROM "orders"
INNER JOIN "users" ON ("orders"."user_id" = "users"."id")
WHERE "users".account_id = 4500000;
The results from this query take about 45s to return. If we run the explain analyze in this query, we will see that the join is taking too long, even though it is a simple query.
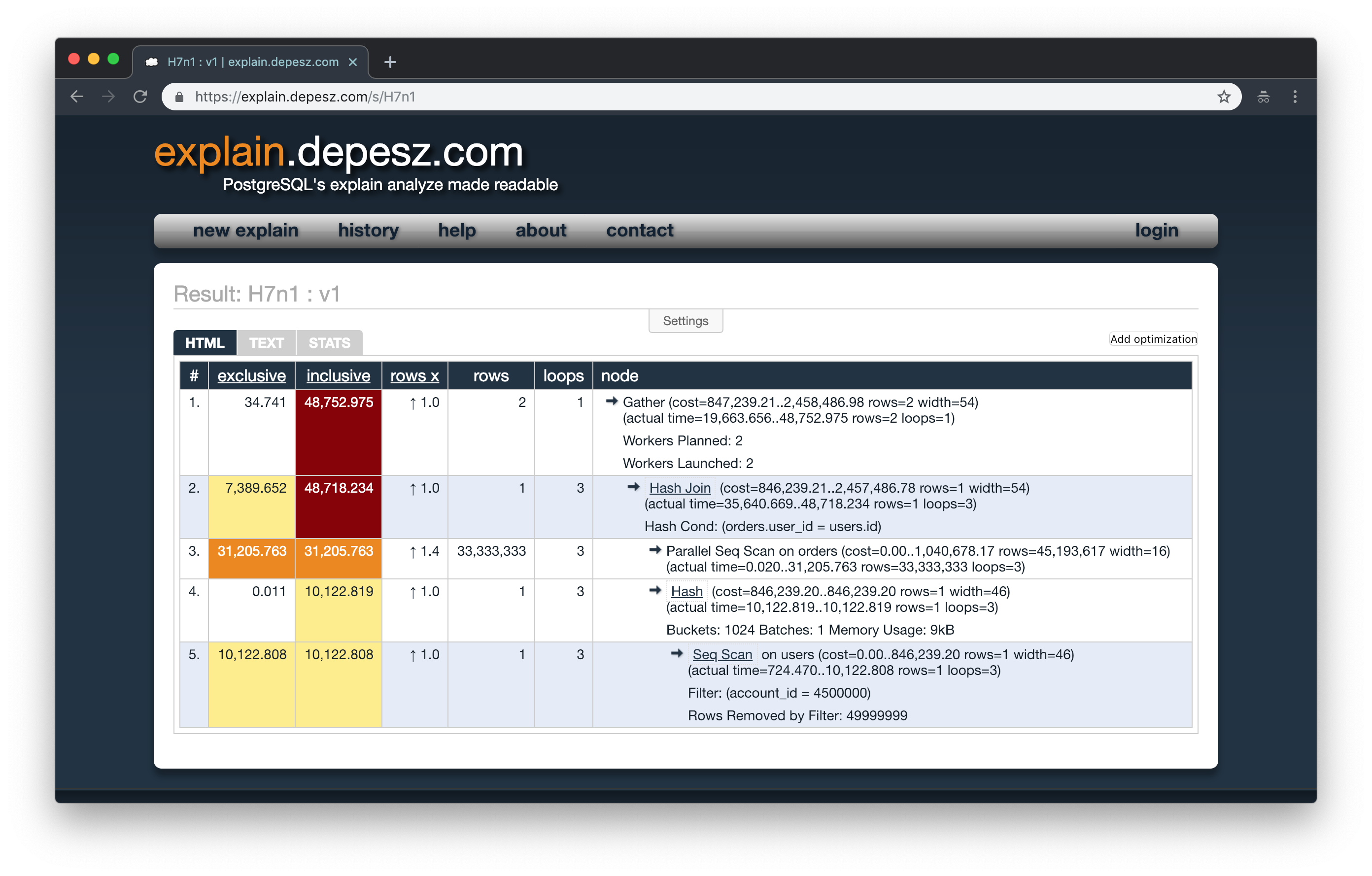
One of the things we can do to improve this query is to denormalize the orders table and create another column user_account_id that will be a copy of the account_id column from the users table. This way we can remove the join and make it easier to read the info.
ALTER TABLE "orders" ADD COLUMN "user_account_id" integer;
If we weren’t dealing with such large data, the easiest way of doing it would be to write a simple UPDATE FROM and go on with life, but with this much of data it could take too long to finish.
UPDATE orders
SET user_account_id = users.account_id
FROM users
WHERE orders.user_id = users.id;
Updating records in batches
One way that we will explore in this blog post is to migrate this amount of data using a script that performs the update in batches.
We will need to control the items to be updated, if your table has a sequential id column it will be easy, otherwise, you will need to find a way to iterate through the records. One way you can control this is through creating another table or temp table, to store the data that needs to be changed, you could use a ROW_NUMBER function to generate the sequential ID or just create a sequential column. The only limitation with temp table is the database hardware that needs to be able to handle this much of records in memory.
PostgreSQL: Documentation: 9.3: CREATE TABLE
Lucky us, we have a sequential column in our table that we can use to control the items. To iterate through the records in PostgreSQL you can use some control structures such as FOR or WHILE.
PostgreSQL: Documentation: 9.2: Control Structures
You can also print some messages during the process to provide some feedback while the queries are running, chances are that it may take a while to finish if you are dealing with a large dataset.
https://www.postgresql.org/docs/9.6/plpgsql-errors-and-messages.html
DO $
DECLARE
row_count integer := 1;
batch_size integer := 50000; -- HOW MANY ITEMS WILL BE UPDATED AT TIME
from_number integer := 0;
until_number integer := batch_size;
affected integer;
BEGIN
row_count := (SELECT count(*) FROM orders WHERE user_account_id IS NULL);
RAISE NOTICE '% items to be updated', row_count;
-- ITERATES THROUGH THE ITEMS UNTIL THERE IS NO MORE RECORDS TO BE UPDATED
WHILE row_count > 0 LOOP
UPDATE orders
SET user_account_id = users.account_id
FROM users
WHERE orders.user_id = users.id
AND orders.id BETWEEN from_number AND until_number;
-- OBTAINING THE RESULT STATUS
GET DIAGNOSTICS affected = ROW_COUNT;
RAISE NOTICE '-> % records updated!', affected;
-- UPDATES THE COUNTER SO IT DOESN'T TURN INTO AN INFINITE LOOP
from_number := from_number + batch_size;
until_number := until_number + batch_size;
row_count := row_count - batch_size;
RAISE NOTICE '% items to be updated', row_count;
END LOOP;
END $;
Given us a message output will be like this until the script finishes:
NOTICE: 200000000 items to be updated
CONTEXT: PL/pgSQL function inline_code_block line 12 at RAISE
NOTICE: -> 50000 records updated!
CONTEXT: PL/pgSQL function inline_code_block line 23 at RAISE
NOTICE: 199950000 items to be updated
CONTEXT: PL/pgSQL function inline_code_block line 30 at RAISE
NOTICE: -> 50001 records updated!
After the script finishes, we can create an index in the new column since it will be used for reading purposes.
CREATE index ON "orders" ("user_account_id");
If we ran the EXPLAIN ANALYZE command again we can see the performance improvements.
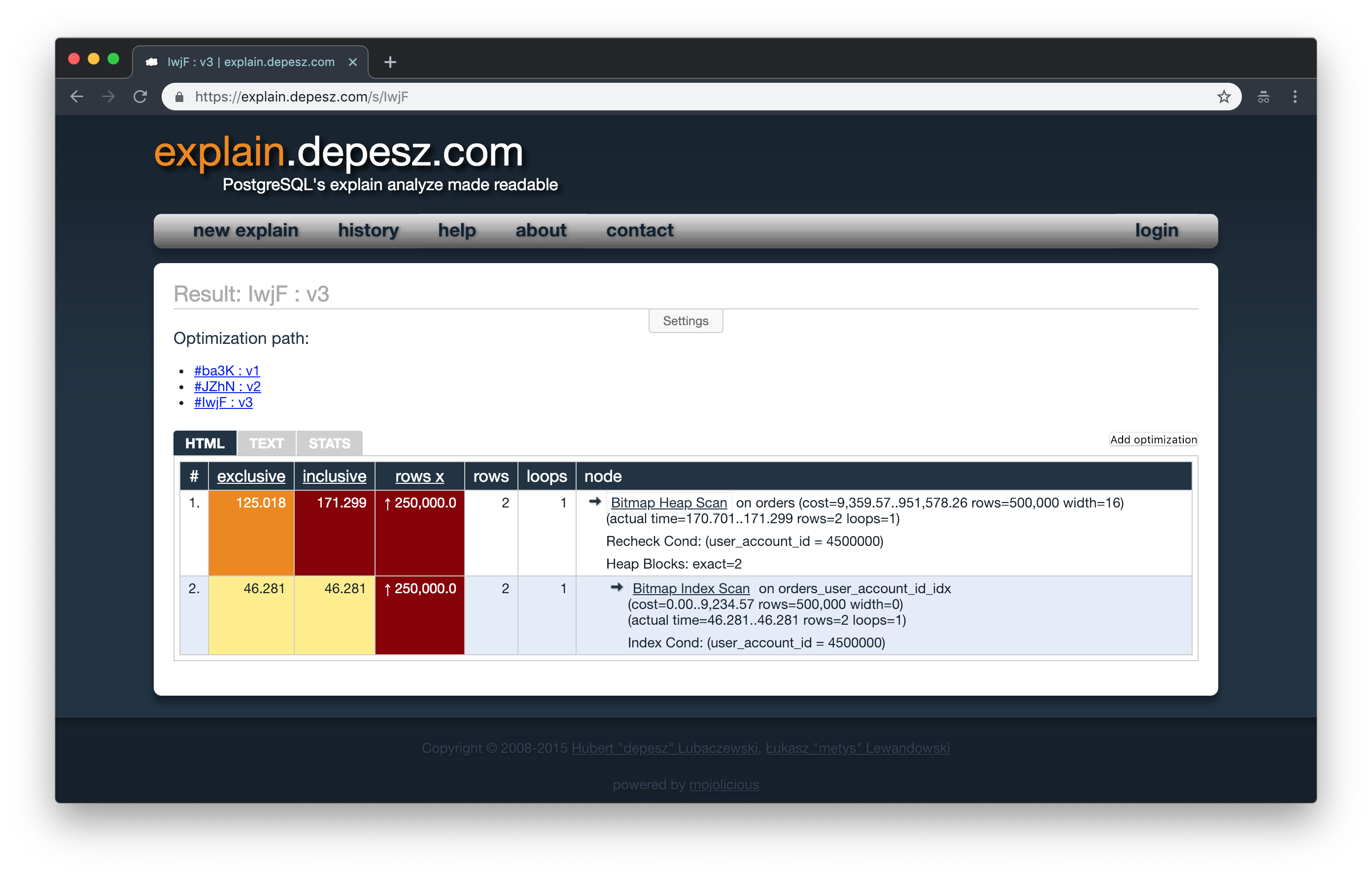
We can see that before, only the join was taking a little bit more than 7s in the query, approximately 15% of the loading time. If we look closer, we can also notice that the next three lines were related to the join, and after we denormalized the table they were gone too.
You can follow the EXPLAIN ANALYZE evolution here
Hope it helps!